Building a Second Brain
Несколько лет назад была написана статья про para. С того момента прошло уже 4 года, и Тиаго Форте решил порадовать своей книгой про подход “building a second brain”. Пробежав по главам, понял что не хочу её читать, так как они содержали все известные статьи из блога. Это было ошибкой. Ведь свои подходы надо итерировать.
Начнём с того, что building a second brain - это методология по ведению персональной базы знаний. Она включает в себя приёмы по организации и обработке информации. В результате накопленный опыт аккумулируется в ней в виде отдельных промежуточных блоков / intermediate packets. Эти блоки можно комбинировать как лего для новых проектов, чтобы не начинать с чистого листа
Основной подхода служит принцип CODE. Это акроним от первых букв слов: Capture, Organise, Distil и Exctract. Под капотом этот принцип использует подходы дивергентного и конвергентного мышления. В рамках дивергентного состояния надо быть открытым ко всему и не критиковать себя. А вот на конвергентной стадии надо собирать полученные знания в непротиворечивую модель.
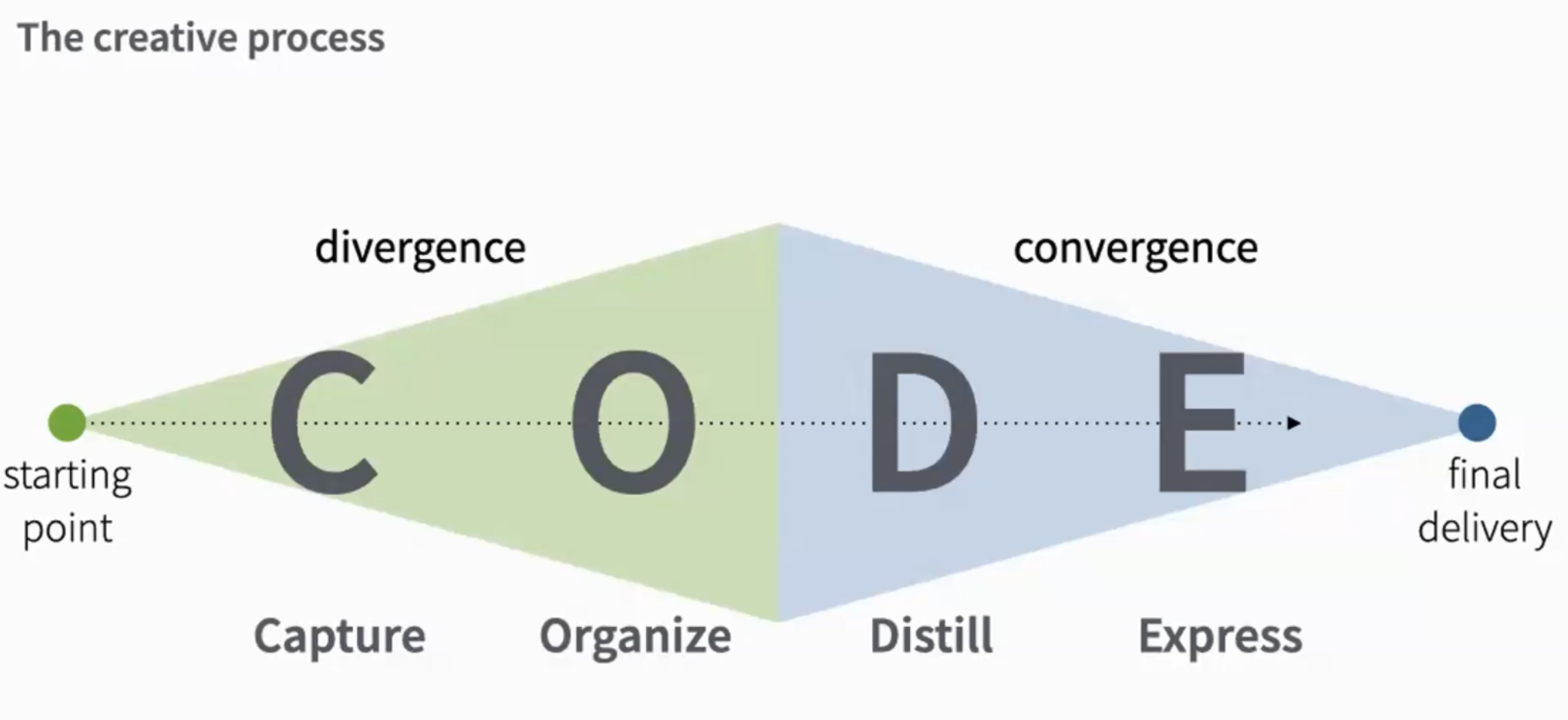
Capture
Творческий процесс заключается не только в создание нового, но и в грамотном синтезе доступных знаний. Чтобы их не терять, стоит настроить приложения и интегрировать их с заметками:
- для чтения статей: getpocket, instapaper, wallabag;
- для чтения книг: kindle, koreader;
- для сохранения отдельных цитат: zotero, readwise;
Но приложения - это самая простая часть данного этапа.
Основная сложность заключается в том, что сохранять. Здесь могут быть две потенциальные проблемы: сохраняем всё подряд или не сохраняем ничего. Ответ автора на этот вопрос заключается в том, чтобы сохранять всё, что резонирует. Так как мы не очень понимаем, что нам понадобиться в дальнейшем. Момент с резонансом здесь самый тонкий. С одной стороны, интуиция человека выдаёт быстрое и, как правило, верное решение на основании поверхностного изучения. С другой стороны, можно стать Плюшкиным.
Organize
Сохраняя большое количество информации нужно понимать, как они в итоге попадут в заметке. И здесь мы возвращаемся к подходу PARA. PARA опять является акронимом от первых букв: Projects, Areas, Resources и Archive. Это название корневых директорий во всех инструментах, которыми вы пользуетесь будь это заметки, облачное хранилище или папки на компьютере.
Из блога мне не хватило аналогий для понимания значения метода. Суть не только в том, чтобы информация лежала единообразно или что мы разделяем проекты от ресурсов. А в том, что мы сортируем контент по его применимости/actionability. Мы можем провести аналогию с кухней: запасы идут в погреб (Archive), то что будет нужно в течение полугода в морозилке (Resources), чуть более востребованное в холодильнике (Areas), а то к чему возвращаемся несколько раз в день непосредственно на столе (Projects). Продолжая аналогию, мы размещаем картинки дизайна квартир с пинтерест в Resources, так как сейчас никакого ремонта нет. А вот статья про налаживание сна у младенца нам пригодится в рамках проекта первого года жизни ребёнка.
Distill
Для эффективного использования накопленных заметок необходимо их осмыслить. Это можно делать с помощью составления выдержек. Подходом автора для решения этой задачи является метод “прогрессивная суммаризация”. По названию и возможно сути перекликается с прогрессивным jpeg’ом.
При прочтении статьи мы выделяем 3-5 абзацев, которые считаем наиболее важными. Потом в них мы выделяем предложения, которые являются важными. А потом мы составляем выдержку по тому, что выделили. Таким образом статью мы сможем вспомнить за несколько предложений, но ещё и пройтись по пути обратно, если нам нужно будет докопаться до сути. Эта идея перекликается из другой недавно прочтённой книгой Ackoff’s best, где были проведены исследования что любой материал можно сократить в 3 раза.
Самое интересное, что автор показывал пример со статьёй из wikipedia. Что помогает понять, что таким образом можно держать и те статьи, что всегда доступны в интернете. Делается это для того, чтобы быстро вспомнить о чём речь.

Express
Полученные выдержки, мы можем начинать использовать в своих проектах. Это помогает избежать проблемы чистого листа. Стартуя новый проект, мы можем пробежаться по ключевым заметкам в ресурсах и соединить те, которые представляют интерес. Данный подход называется архипелаг идей.
Если после начального освящения, трудности с первым шагом, то можно не прыгать сразу к результату. Любой проект - это путь, где следующий шаг может быть очевидным, а фактический результат сильно расходится от запланированного. Главное оставлять себе хлебные крошки к следующему шагу: написали структуру поста –> оставьте вопросы, которые хотелось бы осветить. Этот подход называется Hemingway bridge.
Проект выходит из под контроля - флексим. В книге подход с уменьшением размера проекта назван dial down. Но в прочтении от бюро Горбунова он выглядит более цельным, поэтому тут только порекомендую ознакомиться ссылкой.
Но эти все подходы направлены на использование информации в проектах, в то время как основные знания мы получаем по их завершению. И тут building a second brain начинает работать. По завершению проекта мы должны провести его ревью. В связанных заметках, встречах и остальных материалах появиться новое знание, которое будет полезно для нас в будущем.
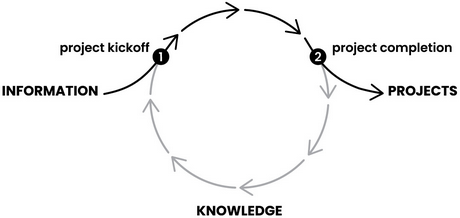
И эти обезличеные знания то, чем стоит делиться. Каждый человек - уникален и второго такого с такими же знаниями и опытом нет. Поэтому надо приходить в локальные сообщества и показывать результат своих мыслей. Ведь любой человек нуждается в самореализации.
Что поменялось в моих подходах после прочтения?
После двух лет использования PARA, произошла реорганизация заметок. Ёкнуло у меня в тот момент, когда увидел репозиторий Life-Disciplines-Projects. Это был уже третий подход в рамках obsidian, и пришло осознание, что не важно что ты используешь, гораздо важнее чтобы было самому удобнее. Сейчас корневые директории в своих заметках держу такие: Actions, Journal, Life, Knowledge, Trash. И для внешнего взгляда они наверное ничего не значат. Но из книги увидел, что организация пошла точно так же по степени востребованности.
Буду перерабатывать подходы к составлению заметок из статей. Сейчас они разбиваются на цитаты, а надо бы собирать их в одну атомарную заметку. Но дальше начинается вопрос переиспользовать ли этот подход для книг, и тут уже начинают плавать. В любом случае, прогрессивную суммаризацию точно стоит провести в виде эксперимента и адаптировать.
По результатам мне хотелось бы уже переключиться на свои заметки вместо гугл поиска. Кстати, люди делали такой эксперимент и оно работает. Подробнее почитать можно тут.
Чеклист внедрения из книги
- Выбрать для чего мы хотим вести заметки.
- Выбрать приложение для ведения заметок и остаться с ним на полгода.
- Выбрать приложение для сохранения статей.
- Сделать себе структуру папок с помощью PARA.
- Составить список открытых больших вопросов, с помощью которых можно будет фильтровать весь входящий контент.
- Настроить автоматическую синхронизацию заметок из книг в заметки.
- Практиковать progressive summarization на статьях из пункта 3.
- Начать писать атомарные заметки для себя в будущем.
- Начать использовать свои заметки на одном из проектов.
- Поставить себе еженедельное ревью с двумя шагами: просмотреть заметки за неделю и составить следующие шаги по проекту.
- Присоединиться к локальным сообществам по ведению заметок, чтобы находить новые идеи.
- В русскоязычном телеграмме могу рекомендовать чат Zettelkasten и их форум.